A Pharma Supply Chain Engineering Perspective · tech4nirvana.com
Why This Migration Is Non-Trivial
Earlier, I worked as Product Owner and Data Architect on a SAS to Databricks migration for a Pharma Supply Chain and Manufacturing client. One deliverable stood out: migrating Statistical Process Control (SPC) logic — specifically the 8 SPC Run Rules — from SAS Data Step to PySpark.
SPC is a regulatory obligation in pharmaceutical manufacturing. Run rules operationalize this — they catch statistical signals before a measurement breaches a hard specification limit.
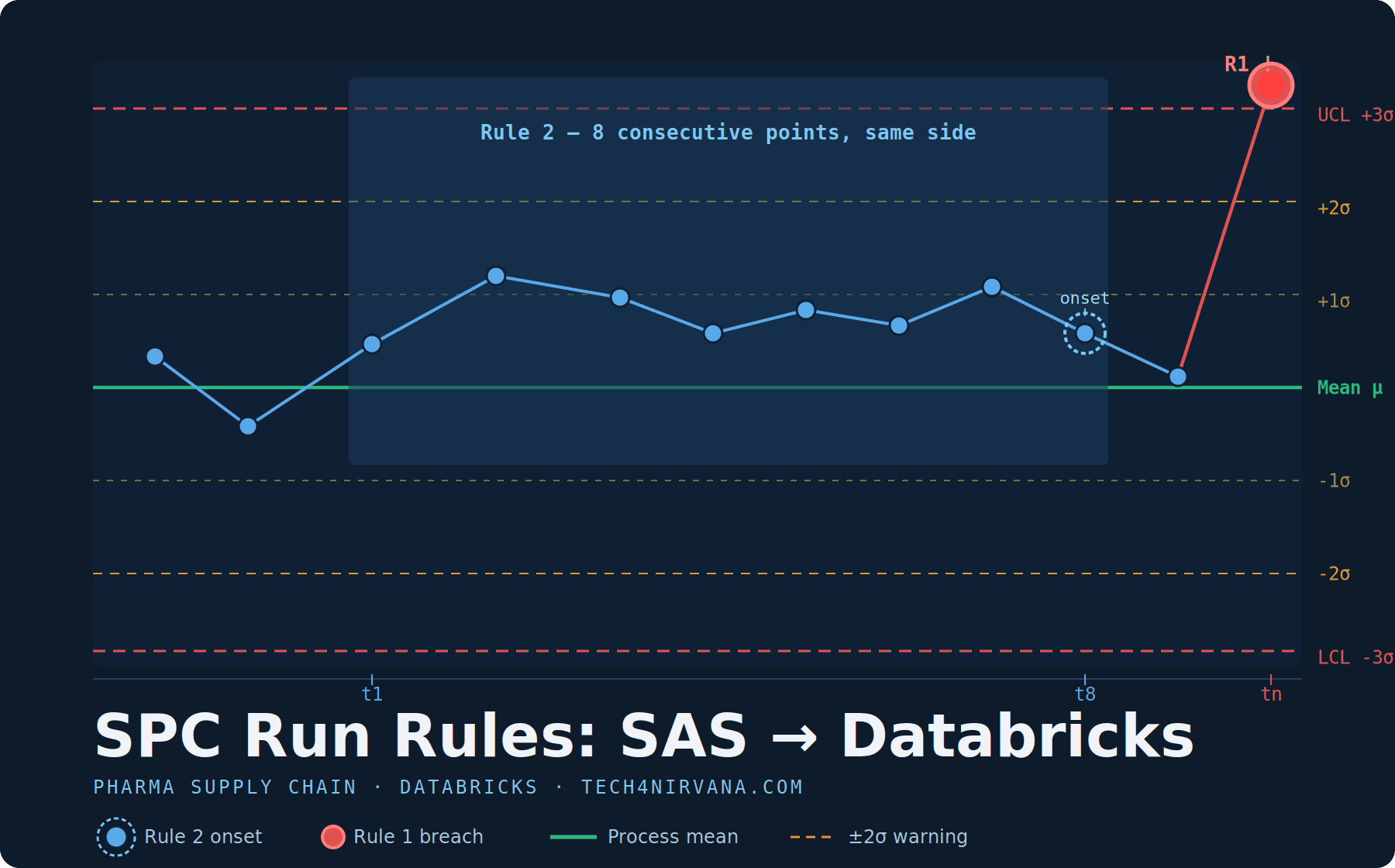
Why 8 points for Rule 2? Rule 2 uses 8 consecutive points on one side of the mean. This reflects a deliberate sensitivity trade-off widely adopted in pharma LIMS/QMS systems — a slightly more sensitive threshold where the cost of a missed shift outweighs the cost of an extra investigation.
The 8 SPC Run Rules
| Rule |
Condition |
Threshold |
Signal |
| R1 |
Point beyond 3σ |
1 point > ±3σ |
Assignable cause |
| R2 |
Run one side of mean |
8 consecutive same side |
Process shift |
| R3 |
Monotonic trend |
6 consecutive increasing/decreasing |
Drift / tool wear |
| R4 |
Alternating pattern |
14 alternating up/down |
Systematic oscillation |
| R5 |
2 of 3 near outer limit |
2 of 3 consecutive > ±2σ, same side |
Incipient shift |
| R6 |
4 of 5 near 1σ |
4 of 5 consecutive > ±1σ, same side |
Consistent drift |
| R7 |
Stratification |
15 consecutive within ±1σ |
Over-control |
| R8 |
Mixture |
8 consecutive outside ±1σ, either side |
Bimodal / mixture |
The SAS Paradigm
SAS Data Step processes one row at a time. The RETAIN statement persists values across iterations — making run-counter logic trivial:
/* Rule 2 in SAS — naturally sequential */
data spc_out;
set process_data;
retain run_count 0 last_side ' ';
/* All three cases must be explicit — on-mean points break the run */
if value > mean then side = 'A';
else if value < mean then side = 'B';
else side = 'C';
if side = 'C' then do;
run_count = 0;
last_side = 'C';
end;
else if side = last_side then run_count + 1;
else do;
run_count = 1;
last_side = side;
end;
/* fires EXACTLY at the 8th point — onset semantics are free */
rule_2 = (run_count = 8);
run;
Three properties make SAS the natural host:
Implicit cursor — PDV advances one row at a time
Persistent state — via RETAIN, free and automatic
Onset detection — trivially correct; fires when run_count == 8, resets on side-change or on-mean point
Four Spark Challenges
1. No shared cursor
A Spark DataFrame is distributed across many executors — there is no single sequential pass. Solution: Window.partitionBy('batch_id', 'parameter_name').orderBy('measurement_timestamp') guarantees correct ordering within a partition-window. Ensure that batch_id and parameter_name define complete logical boundaries and that chronological ordering is never disrupted at partition edges. Validate with synthetic boundary-crossing test data before deploying to production.
2. No implicit state — and memory pressure
SAS RETAIN has no Spark equivalent. The idiomatic bridge: collect_list() over a Window frame + Higher-Order Functions (aggregate(), forall(), slice()) applied to the resulting ordered array.
One operational constraint is important: collect_list() pulls all values in the window into a single executor's memory. For an SPC batch with millions of sensor readings per batch_id, this can trigger OutOfMemory errors. The mitigation is straightforward — use a bounded window (rowsBetween(-14, 0)) rather than unbounded preceding. Since no SPC rule requires more than 15 contiguous observations, capping the array at 15 elements eliminates the memory risk without any loss of rule accuracy.
For very high-scale deployments, a Pandas UDF approach can achieve significantly better throughput — see Vectorized Approach below.
3. Onset detection is not free
A naive HOF check (exists(), forall()) fires at positions N, N+1, N+2 — re-triggering on the same run. The fix: a named_struct accumulator inside aggregate() that tracks (last_side, run_len), incrementing on continuation and resetting on side-change or on-mean observation. The rule fires only when run_len == exactly N.
4. Cross-batch state loss
In a batch SPC pipeline, if a run of 8 points straddles two incremental loads — 5 points in Job A, 3 points in Job B — the window-based accumulator loses state between jobs and will not fire. For near-real-time or incremental SPC monitoring, the correct pattern is Stateful Structured Streaming with mapGroupsWithState(), which persists run state across micro-batches via a checkpoint. See Cross-Batch Runs below.
PySpark Implementation
Setup
from pyspark.sql import functions as F
from pyspark.sql.window import Window
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType
# Bounded window — caps array at 15 elements, satisfying all SPC rule windows
# and preventing executor OOM on large batches
w_bounded = Window.partitionBy('batch_id', 'parameter_name') \
.orderBy('measurement_timestamp') \
.rowsBetween(-14, 0)
vals = F.collect_list('value').over(w_bounded)
sigma = F.first('sigma').over(w_bounded)
mean_val = F.first('mean_val').over(w_bounded)
# Normalised z-score array
z_arr = F.transform(vals, lambda x: (x - mean_val) / sigma)
Handling missing values: SPC rules are sensitive to gaps in measurement_timestamp. A gap in the time series should reset run counters — the run has been interrupted. Pre-process the DataFrame to detect gaps before windowing:
w_order = Window.partitionBy('batch_id', 'parameter_name') \
.orderBy('measurement_timestamp')
df_gap_aware = df.withColumn(
'prev_timestamp',
F.lag('measurement_timestamp').over(w_order)
).withColumn(
'gap_exceeded',
(F.unix_timestamp('measurement_timestamp') -
F.unix_timestamp('prev_timestamp')) > 300 # 5-minute threshold — adjust per SOP
)
# Partition on gap boundaries so each continuous segment is windowed independently
# Implementation depends on your SOP — filter, flag, or introduce a segment_id column
Document the gap threshold in your data dictionary. This is a business rule, not a Spark concern.
Rule 1 — Single point beyond 3σ
rule1 = F.abs(z_arr.getItem(F.size(z_arr) - 1)) > 3.0
Rule 2 — Onset-correct 8-point run
Values exactly at the mean (z = 0) break the run — the same behaviour as the SAS side = 'C' case. The accumulator resets to 0 on an on-mean observation, resets to 1 on a side change, and increments on continuation. The rule fires at exactly the 8th consecutive point — not before, not after.
def side_of(z):
"""Return 1 (above mean), -1 (below mean), or 0 (on mean)."""
return F.when(z > 0, F.lit(1)) \
.when(z < 0, F.lit(-1)) \
.otherwise(F.lit(0))
rule2 = F.aggregate(
z_arr,
F.named_struct(
F.lit('last_side'), F.lit(0),
F.lit('run_len'), F.lit(0)
),
lambda acc, z: F.named_struct(
F.lit('last_side'), side_of(z),
F.lit('run_len'),
F.when(
(side_of(z) != F.lit(0)) & (side_of(z) == acc['last_side']),
acc['run_len'] + 1 # Continue run on same side
).when(
side_of(z) != F.lit(0), # Side change
F.lit(1) # Start new run at 1
).otherwise(
F.lit(0) # On-mean: reset
)
),
lambda acc: acc['run_len'] == 8 # Fire at exactly the 8th point
)
Validation contract:
7 points above mean → rule2 = False
8 points above mean → rule2 = True at position 8 only
9 points above mean → rule2 = False (no re-fire)
8 above, 1 on-mean, 8 above → fires at positions 8 and 17 (two separate runs)
Rule 3 — 6 consecutive trending points (onset detection)
The accumulator tracks {prev, dir, run}. Direction is computed once per step from the current and previous z-score, stored in dir, and compared against acc['dir'] in the next step. A flat step (equal consecutive values) breaks the trend and resets the streak.
# Rule 3: 6 consecutive points strictly increasing or decreasing
# Accumulator fields:
# prev — previous z-score (null sentinel on first observation)
# dir — +1 increasing, -1 decreasing, 0 flat or first step
# run — current streak length
def _current_dir(z, prev):
"""Direction from prev to z. Null prev → no direction."""
return (
F.when(prev.isNull(), F.lit(0))
.when(z > prev, F.lit(1))
.when(z < prev, F.lit(-1))
.otherwise(F.lit(0))
)
rule3 = F.aggregate(
z_arr,
F.named_struct(
F.lit('prev'), F.lit(None).cast('double'),
F.lit('dir'), F.lit(0),
F.lit('run'), F.lit(0)
),
lambda acc, z: F.named_struct(
F.lit('prev'), z,
F.lit('dir'), _current_dir(z, acc['prev']),
F.lit('run'),
F.when(
acc['prev'].isNotNull() &
(_current_dir(z, acc['prev']) == acc['dir']) &
(acc['dir'] != F.lit(0)),
acc['run'] + 1 # Continue trend
).otherwise(
F.lit(1) # New direction, flat, or first step
)
),
lambda acc: (acc['run'] == 6) & (acc['dir'] != 0) # Fire at exactly 6th point
)
Rule 4 — 14 alternating points
For each inner point in the last 14 observations, the product of the left and right deltas must be negative — confirming a direction reversal at every step.
# Rule 4: 14 consecutive points alternating up/down
# last14 indices: 0 .. 13
# Inner loop: i = 1 .. 12, accessing i-1 (0..11), i (1..12), i+1 (2..13) — all safe
last14 = F.slice(z_arr, F.size(z_arr) - 13, 14)
rule4 = (F.size(z_arr) >= 14) & F.aggregate(
F.sequence(F.lit(1), F.lit(12)), # 12 inner points; accesses indices 0..13
F.lit(True),
lambda acc, i: acc & (
((last14.getItem(i) - last14.getItem(i - 1)) *
(last14.getItem(i + 1) - last14.getItem(i))) < 0
)
)
Rules 5, 6, 7, 8 — Window patterns
# Rule 5: 2 of 3 consecutive beyond ±2σ, same side
last3 = F.slice(z_arr, F.size(z_arr) - 2, 3)
above2 = F.aggregate(last3, F.lit(0), lambda a, z: a + F.when(z > 2.0, F.lit(1)).otherwise(F.lit(0)))
below2 = F.aggregate(last3, F.lit(0), lambda a, z: a + F.when(z < -2.0, F.lit(1)).otherwise(F.lit(0)))
rule5 = (F.size(z_arr) >= 3) & ((above2 >= 2) | (below2 >= 2))
# Rule 6: 4 of 5 consecutive beyond ±1σ, same side
last5 = F.slice(z_arr, F.size(z_arr) - 4, 5)
above1 = F.aggregate(last5, F.lit(0), lambda a, z: a + F.when(z > 1.0, F.lit(1)).otherwise(F.lit(0)))
below1 = F.aggregate(last5, F.lit(0), lambda a, z: a + F.when(z < -1.0, F.lit(1)).otherwise(F.lit(0)))
rule6 = (F.size(z_arr) >= 5) & ((above1 >= 4) | (below1 >= 4))
# Rule 7: 15 consecutive within ±1σ (stratification)
last15 = F.slice(z_arr, F.size(z_arr) - 14, 15)
rule7 = (F.size(z_arr) >= 15) & F.forall(last15, lambda z: F.abs(z) <= 1.0)
# Rule 8: 8 consecutive beyond ±1σ, either side (mixture)
last8 = F.slice(z_arr, F.size(z_arr) - 7, 8)
rule8 = (F.size(z_arr) >= 8) & F.forall(last8, lambda z: F.abs(z) > 1.0)
Mutual exclusivity — priority waterfall
Each observation receives exactly one rule label. Priority: R1 → R2 → R5 → R6 → R3 → R4 → R7 → R8 — severity-first, consistent with pharma QMS convention.
df_out = df.withColumn('spc_rule',
F.when(rule1, F.lit('R1_3sigma'))
.when(rule2, F.lit('R2_run8_same_side'))
.when(rule5, F.lit('R5_2of3_beyond_2sigma'))
.when(rule6, F.lit('R6_4of5_beyond_1sigma'))
.when(rule3, F.lit('R3_trend6'))
.when(rule4, F.lit('R4_alternating14'))
.when(rule7, F.lit('R7_stratification15'))
.when(rule8, F.lit('R8_mixture8'))
.otherwise(F.lit('NO_SIGNAL'))
).withColumn('rule_fired_at_timestamp', F.current_timestamp())
Vectorized Approach (Pandas UDF)
For high-scale deployments — millions of sensor readings per batch — Pandas UDFs execute NumPy operations in vectorized batches on the executor, avoiding JVM serialization overhead. This can be significantly faster than nested Spark SQL HOFs for complex multi-rule logic.
When to prefer Pandas UDFs:
Processing 1M+ rows per batch_id
Rules require NumPy/SciPy (e.g., EWMA, rolling z-test)
Multiple rules computed in a single pass
import pandas as pd
import numpy as np
from pyspark.sql.functions import pandas_udf
from pyspark.sql.types import StructType, StructField, BooleanType
@pandas_udf(
StructType([
StructField('rule2_fired', BooleanType(), True),
StructField('rule3_fired', BooleanType(), True),
])
)
def spc_rules_vectorized(z_values: pd.Series) -> pd.DataFrame:
"""Compute Rule 2 and Rule 3 for an ordered window of z-scores."""
z = z_values.values # NumPy array
# Rule 2: 8 consecutive same side (onset detection)
rule2_result = np.zeros(len(z), dtype=bool)
run_len, last_side = 0, 0
for i, zi in enumerate(z):
side = 1 if zi > 0 else (-1 if zi < 0 else 0)
if side == 0:
run_len, last_side = 0, 0
elif side == last_side:
run_len += 1
else:
run_len, last_side = 1, side
rule2_result[i] = (run_len == 8)
# Rule 3: 6 consecutive trending (onset detection)
rule3_result = np.zeros(len(z), dtype=bool)
run_len, last_dir, prev_z = 0, 0, None
for i, zi in enumerate(z):
if prev_z is None:
prev_z = zi
continue
cur_dir = 1 if zi > prev_z else (-1 if zi < prev_z else 0)
if cur_dir == 0:
run_len, last_dir = 0, 0
elif cur_dir == last_dir:
run_len += 1
else:
run_len, last_dir = 1, cur_dir
rule3_result[i] = (run_len == 6) and (last_dir != 0)
prev_z = zi
return pd.DataFrame({'rule2_fired': rule2_result, 'rule3_fired': rule3_result})
Cross-Batch Runs (Stateful Streaming)
Production pharma SPC systems often operate in near-real-time: measurements arrive as they are taken, not in daily batch files. If a run of 8 points straddles two micro-batches — 5 points in the first, 3 in the second — the window-based accumulator loses state at the batch boundary and will not fire the rule.
The correct pattern is mapGroupsWithState() in Spark Structured Streaming, which persists (last_side, run_len) in a managed state store across micro-batches.
from dataclasses import dataclass
from typing import Iterator
from pyspark.sql.streaming import GroupState, GroupStateTimeout
from pyspark.sql import Row
@dataclass
class SpcRunState:
last_side: int = 0
run_len: int = 0
def update_spc_state(
group_key: tuple, # (batch_id, parameter_name)
measurements: Iterator[Row],
state: GroupState
) -> Iterator[Row]:
"""
Stateful SPC Rule 2 processor.
Preserves run state across Spark micro-batches.
"""
current = state.get if state.exists else SpcRunState()
results = []
for row in sorted(measurements, key=lambda r: r.measurement_timestamp):
z = row.z_score
side = 1 if z > 0 else (-1 if z < 0 else 0)
if side == 0:
current.run_len, current.last_side = 0, 0
rule2_fired = False
elif side == current.last_side:
current.run_len += 1
rule2_fired = (current.run_len == 8)
else:
current.run_len, current.last_side = 1, side
rule2_fired = False
results.append({**row.asDict(), 'rule2_fired': rule2_fired})
state.update(current)
yield from results
# Apply:
df_stream = (
spark.readStream
.schema(input_schema)
.load('/mnt/bronze/sensor_stream')
.withColumn('z_score', (F.col('value') - F.col('mean')) / F.col('sigma'))
.groupby('batch_id', 'parameter_name')
.applyInPandasWithState(
update_spc_state,
output_schema,
state_schema,
'append',
GroupStateTimeout.ProcessingTimeTimeout()
)
)
df_stream.writeStream \
.option('checkpointLocation', '/checkpoints/spc_stream') \
.option('mergeSchema', 'true') \
.toTable('gold_spc_alerts')
.start()
| Pattern |
When to use |
collect_list() + bounded window |
Atomic daily batch where all measurements for a batch_id arrive in one job |
mapGroupsWithState() |
Incremental or streaming loads where a run may span multiple jobs or micro-batches |
Unit Testing Edge Runs
Before deploying to a validated pharma environment, test the accumulator logic explicitly against boundary conditions. These tests should be part of your CI/CD pipeline.
def test_rule2_fires_at_exactly_8():
"""No early fire, no re-fire after position 8."""
z = [0.5] * 9
result = compute_rule2(z)
assert result[6] == False, "Must not fire at position 7"
assert result[7] == True, "Must fire at position 8"
assert result[8] == False, "Must not re-fire at position 9"
def test_rule2_on_mean_resets():
"""On-mean point resets the run; second run fires independently."""
z = [0.5] * 8 + [0.0] + [0.5] * 8
result = compute_rule2(z)
assert result[7] == True, "First run fires at position 8"
assert result[16] == True, "Second run fires at position 17"
def test_rule3_flat_breaks_trend():
"""A flat (equal) step resets the trend counter."""
z = [0.5, 0.6, 0.7, 0.8, 0.9, 1.0, # 5 increasing steps
1.0, # flat — breaks trend
1.1, 1.2, 1.3, 1.4, 1.5, 1.6] # new run of 6
result = compute_rule3(z)
assert result[5] == False, "Broken trend must not fire"
assert result[12] == True, "New run of 6 must fire"
def test_rule4_alternating_14():
"""14 alternating points fires Rule 4."""
z = [0.5, -0.5, 0.6, -0.6, 0.7, -0.7, 0.8, -0.8,
0.9, -0.9, 1.0, -1.0, 1.1, -1.1]
result = compute_rule4(z)
assert result[13] == True, "Rule 4 must fire at 14th alternating point"
def test_rule5_minimum_window():
"""Rule 5 requires at least 3 points."""
z = [2.5]
result = compute_rule5(z)
assert result[0] == False, "Rule 5 must not fire on 1-point window"
def test_cross_batch_rule2():
"""Run spanning two batches fires at overall position 8 via stateful processor."""
state_after_a = process_batch_stateful([0.5] * 5) # 5 above in Batch A
result_b = process_batch_stateful([0.5] * 3, initial_state=state_after_a)
assert result_b[2] == True, "Rule 2 must fire at the 3rd point of Batch B (8th overall)"
SAS vs PySpark
| Dimension |
SAS Data Step |
Databricks (Batch) |
Databricks (Streaming) |
| Execution |
Sequential cursor, single-node |
Distributed DAG, partitioned |
Micro-batch, distributed |
| State |
RETAIN — implicit, free |
aggregate() with named_struct |
mapGroupsWithState() |
| Onset detection |
run_count == N — trivially correct |
Accumulator tracks exact onset |
Stateful processor with explicit reset |
| Memory model |
Sequential disk/buffer |
collect_list() bounded to 15 elements |
Persistent state store |
| Cross-batch runs |
N/A (single pass) |
State lost between jobs |
State preserved via checkpoint |
| Mutual exclusivity |
Chained IF-ELSE, single pass |
when().otherwise() waterfall |
Stream grouping + waterfall |
| Scale |
Memory-bound (~100M rows max) |
Horizontally scalable, petabyte-ready |
Horizontally scalable, low-latency |
| Audit trail |
SAS validated environment |
Delta Lake history + Unity Catalog |
Delta Lake + complete lineage |
Medallion Architecture Placement
| Layer |
Responsibility |
| Bronze |
Raw historian data (PI, DeltaV, LIMS). Full fidelity, no transforms, audit trail intact. |
| Silver |
Cleaned, joined to batch master. Control chart stats computed: mean, sigma, UCL/LCL. z-score arrays built. On-mean handling and gap thresholds documented in data dictionary. |
| Gold |
SPC rules applied. One row per observation + spc_rule flag + rule_fired_at_timestamp. LIMS/Power BI ready. Alerts de-duplicated by (batch_id, parameter_name, rule, timestamp bucket). |
Unity Catalog governance: Catalog pharma_manufacturing → schemas raw, curated, analytics. Delta Lake time-travel supports regulatory investigation. ZORDER on (batch_id, parameter_name, measurement_timestamp) eliminates file scanning on QMS query patterns.
Production Design Considerations
Schema enforcement
Do not hard-code sigma and mean_val as literals. Use broadcast variables for small control limits tables or joins for dynamically computed limits:
# Broadcast: for small, infrequently changing control limits
control_limits_bc = spark.sparkContext.broadcast(
control_limits_df.collect()
)
# Join: for dynamically computed batch-level statistics
df_with_stats = df.join(
control_stats,
on=['batch_id', 'parameter_name'],
how='left'
)
Sigma estimator
Document which estimator was used to compute sigma — moving range, sample SD, pooled, or UWMA. This is a regulatory and statistical decision, not a Spark concern. Example using moving range (the SAS default for individuals charts):
w_order = Window.partitionBy('batch_id', 'parameter_name') \
.orderBy('measurement_timestamp')
df_sigma = df.withColumn(
'moving_range',
F.abs(F.col('value') - F.lag('value').over(w_order))
).withColumn(
'sigma_estimate',
F.avg('moving_range').over(w_order) / 1.128 # d2 constant for n=2
)
Partition alignment
Repartition on (batch_id, parameter_name) before writing Silver and apply ZORDER on timestamp to ensure physical file layout aligns with logical query patterns:
df.repartition('batch_id', 'parameter_name') \
.write.format('delta') \
.mode('overwrite') \
.option('zorderBy', 'batch_id,parameter_name,measurement_timestamp') \
.saveAsTable('silver_spc_zscores')
Alert de-duplication
In operational deployments, the same rule can fire on consecutive rows within a run. Apply a de-duplication layer before writing to your LIMS alerting table:
df_alerts = (
df_out
.filter(F.col('spc_rule') != 'NO_SIGNAL')
.withColumn('alert_id', F.md5(
F.concat_ws('|',
F.col('batch_id'),
F.col('parameter_name'),
F.col('spc_rule'),
F.date_trunc('hour', F.col('rule_fired_at_timestamp'))
)
))
.dropDuplicates(['alert_id'])
)
The Witness and the Process Stream
Patanjali's Yoga Sutras II.17 identifies the root of suffering as the association between the Seer (Drashtri) and the Seen (Drishya). Advaita Vedanta resolves this through Sakshi — the Witness that observes all phenomena without identification or reaction.
A well-designed SPC monitor is, in a small engineering sense, a Sakshi. The process stream flows — measurements rise, fall, drift, oscillate. The system neither panics nor ignores. Rule 1 fires not because the system is alarmed, but because it has accurately perceived what is. The onset-correct accumulator fires exactly once, at the right moment, on the right signal, without noise.
The transition from SAS to Spark mirrors a deeper shift: from implicit state (RETAIN) to explicit state (aggregate(), mapGroupsWithState()). That explicitness demands clarity — you must name your assumptions, test your edge cases, and document your intentions. That rigour is a form of witness-consciousness in code.
Reliable observation requires correct architecture. Turīya — the fourth state of the Mandukya Upanishad — witnesses the three states (waking, dream, deep sleep) without being any of them. The Gold layer, sitting above Bronze and Silver, witnesses the process without being the process.
— tech4nirvana.com
References
FDA 21 CFR Part 211 — Current Good Manufacturing Practice for Finished Pharmaceuticals.
ICH Q10: Pharmaceutical Quality System. 2008.
ICH Q14: Analytical Procedure Development. 2023.
Apache Spark Documentation — Window Functions and Higher-Order Functions.
Databricks Documentation — Delta Lake Time Travel, Unity Catalog, Structured Streaming, mapGroupsWithState.
Apache Spark — Pandas UDFs with Arrow: https://spark.apache.org/docs/latest/sql-pyspark-pandas-with-arrow.html
Patanjali. Yoga Sutras II.17: Drashtri-drishyayoh samyogo heya-hetuh.
Shankaracharya. Mandukya Upanishad Bhashya — on Turīya as the fourth (witnessing) state.